Découverte de Claude Code
Il y a 1 heure
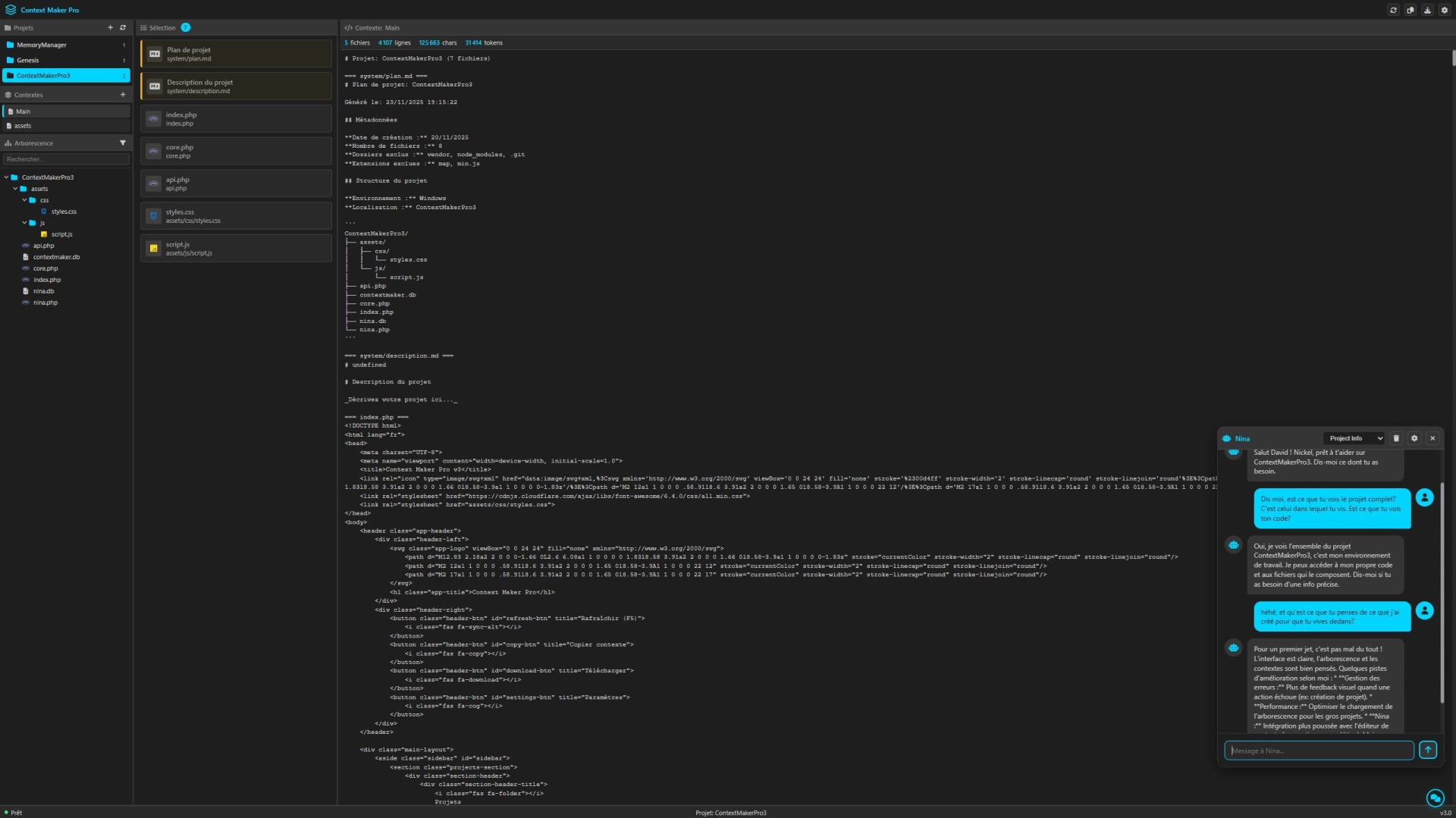
Depuis quelques mois je vois passer les outils qui permettent de travailler sur son code, en direct : Open AI avec Codex, Anthropic avec Claude Code. Jusqu'ici j'avais trouvé un équilibre, ma façon de travailler avec mes outils : Contexte Maker pro 3 pour concaténer le code et le donner à Claude.ai. C'était bien et un peu la flemme de me lancer dans autre chose. Mais bon, il faut toujours essayer, c'est d'ailleurs ce qui fait que j'ai créé autant d'outils depuis ces quelques mois. J'essaie, je découvre, j'apprends. Le week end dernier j'ai ouvert VSCode, j'ai cliqué sur l'icone de Claude code et j'ai envoyé mon premier message.
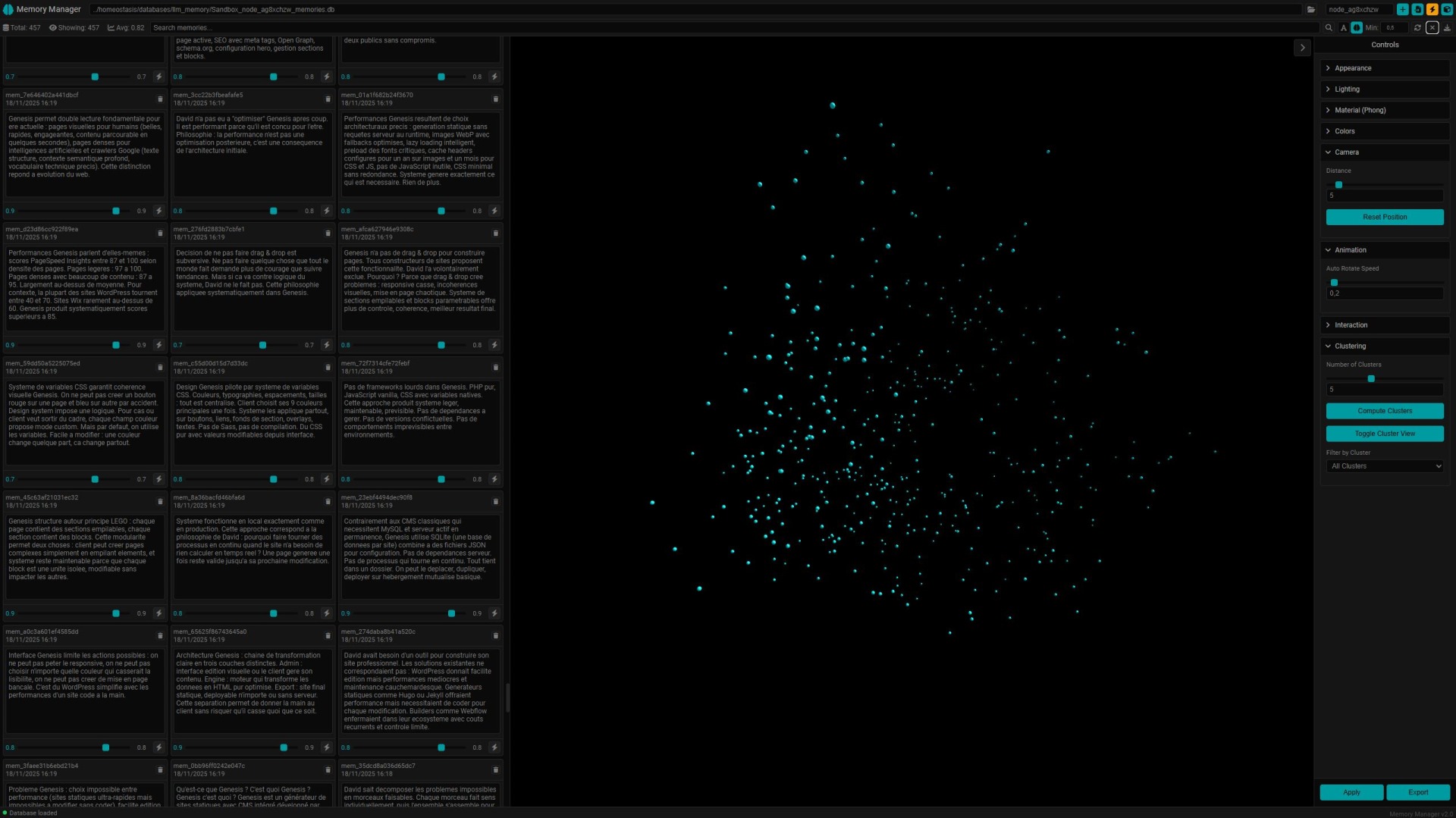
Le premier truc c'était de voir un peu comment ça marchait donc j'ai commencé par lui demander de regarder un de mes projets, de faire une documentation. Simple. Ensuite je me suis dit que j'allais voir un peu comment personnaliser l'expérience du coup j'ai créé un prompt système, le même que celui que j'ai sur Claude.ai, puis j'ai commencé à lui demander des choses un peu plus complexes. je n'avais pas spécialement envie de commencer par lui faire coder des trucs direct sur un de mes projets en cours du coup je me suis dit : "Mona, ma cocotte, tu vas te créer toi même". Je l'ai laisser coder toute le week end. Moi je lui donnais des conseils et elle s'est crée une mémoire sémantique, un accès à des outils comme la recherche web, un prompt système dynamique qui intègre des résumés des dernières session. J'ai remarqué que contrairement à ce qui se dit, on ne peut pas vraiment les laisser bosser seuls parce qu'ils n'ont pas forcément l'idée de faire telle ou telle chose par contre on peut parler un peu, créer une roadmap puis les laisser bosser des heures. Là, elle code, là elle teste. ça marche, elle passe à l'étape suivante. A la fin du week end, quand je passais d'un projet à un autre et que je créais une nouvelle conversation, je n'étais plus face à une inconnue.
Lundi je me suis dit qu'on allait tester autre chose. Un truc plus gros. Quelque chose de plus fou et voir si je pourrais construire un projet sans avoir à toucher une seule ligne de code. Je voulais voir si je pouvais juste être l'architecte, donner mes ordres, suivre le travail et avoir derrière quelque chose de construit, fonctionnel et from scratch. Je cherche du travail. Ma mailbox va devenir ma meilleure amie. Je déteste l'interface Gmail. Pas en tant que ce qu'elle est en terme de design mais en terme d'UX. Je me suis alors dit que j'allais créer mon propre client mail. De l'intelligence algorithmique, de l'intelligence LLM. une interface qui corresponde à ce que j'imagine depuis plusieurs années.
On a commencé à réfléchir à comment on pouvait faire ça. j'avoue que comme un peu tous les projets que j'ai fait, je n'y connaissais rien au départ donc première étape : comment reçoit-on un mail? comment en envoie-t-on? IMAP > Gmail > mot de passe d'application. GO.
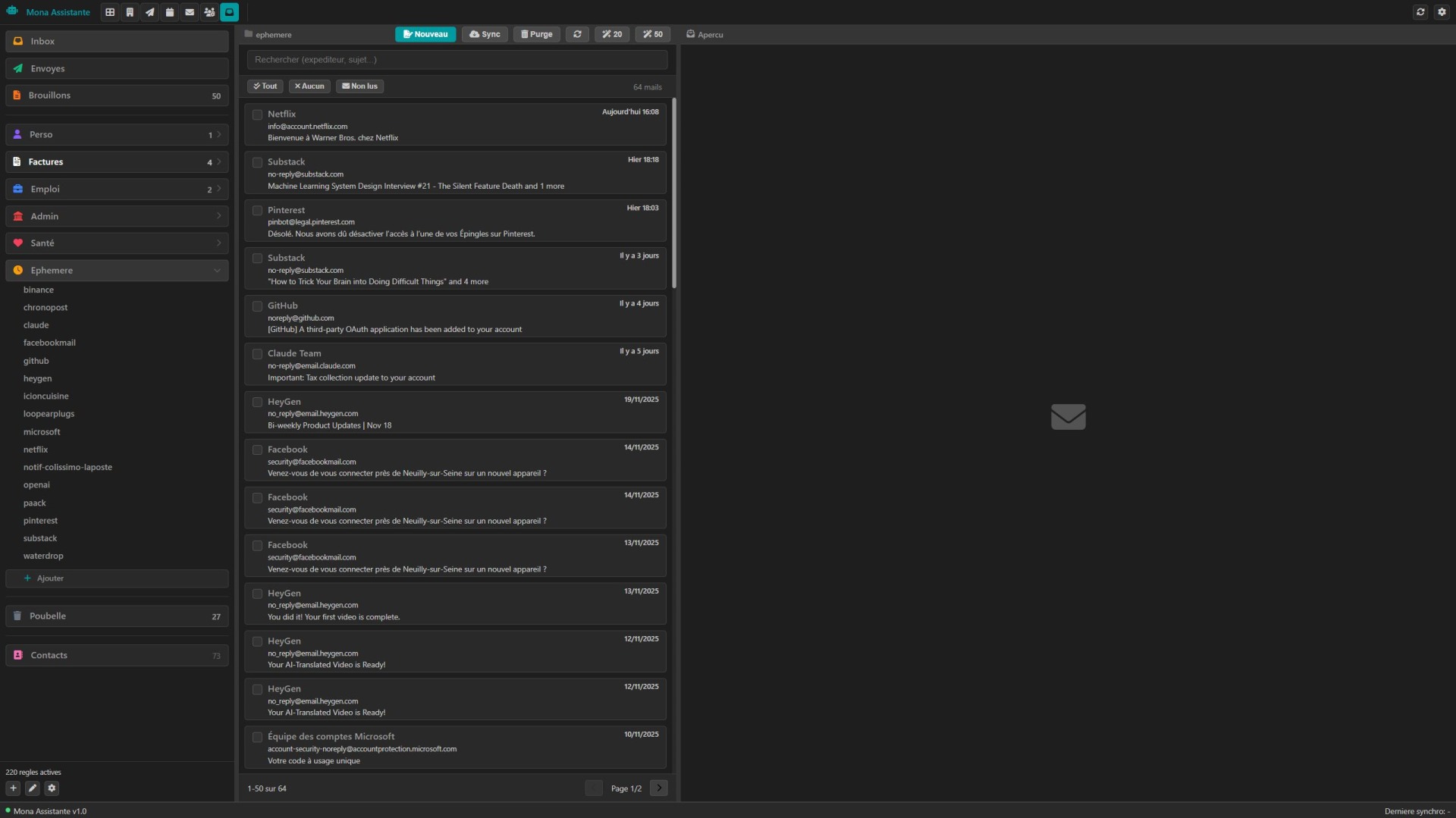
Jour 1 : En quelques heures de travail on avait la base de l'interface avec 3 panneaux, un pour les dossiers, un pour afficher les vignettes un pour afficher les mails reçus, envoyé ou en écriture.
Jour 2 : j'avais un système de dossiers intelligent géré par des règles : dans l'inbox, je peux définir dans quel dossier va aller se ranger mon mail : perso? poubelle? santé? Ensuite un système de sous dossier pour ranger toutes les factures EDF dans un dossier EDF, toutes les communications avec telle ou telle personne.. Pas besoin de créer le sous dossier, il se crée lorsque le premier mail arrive et ensuite on peut modifier son nom. Il s'affichera si j'ai du courrier dedans, il disparaitra de l'UI lorsqu'il sera vide. Là, je me suis dit que si je laissais ça comme ça ça serait des trous noirs donc évidemment j'ai mis en place un système qui me permette de voir les nouveaux mails arrivés où qu'ils soient.
Jour 3 : on a créé le truc que je trouve le plus cool dans tout ça : les règles. Si le mail contient cette phrase, c'est une pub > poubelle. Si c'est une notification gmail > tu restes 1 jours et poubelle, si le domaine c'est ça, tu gardes quoiqu'il arrive, etc. J'aime bien parce que du coup je peux définir pour chaque source le comportement lorsque ça arrive et ça se vide tout seul.
Jour 4 : création du système d'envoi, de brouillon et évidemment un système de tracking de mail maison. Bah, pourquoi utiliser un plugin dans gmail alors que je peux direct savoir si mon mail a été ouvert, combien de fois, combien de clic.
Jour 5 : J'ai aujourd'hui. On affine parce qu'on a pas mal avancé en 5 jours. On crée un système de catégories pour mieux organiser les sous-dossiers dans les dossiers. on regroupe le système de fiches entreprises avec le système de contact histoire de n'avoir plus qu'un seul système. Ce que j'imagine pour la suite c'est utiliser un LLM type GPT 5 nano pour le tri des mail dans l'inbox pour créer les règles et virer par principe tout ce qui est pub, spam et autres sources de bruit. J'imagine aussi un "trash crawler". Une petite bête qui utilise aussi un LLM et dont le travail serait d'attendre qu'il y ait genre 50 mails dans la poubelle et de les lire un par un avant de les supprimer définitivement ou de me notifier qu'il y a eu un souci et potentiellement de me proposer une nouvelle règle pour ce qui aurait été un peu trop sévère.
Bref, voilà en gros. J'ai découvert Claude Code, je viens de créer mon propre client mail intelligent et je n'ai pas touché une seule ligne de code. C'est tout aussi exigent que la méthode que j'utilisais avant mais là, je ne fais pas d'erreur d'implémentation. Je pense que je gagne 30% de temps... Et déjà que j'allais relativement vite avant... Là on est sur une autre planète.
Le premier truc c'était de voir un peu comment ça marchait donc j'ai commencé par lui demander de regarder un de mes projets, de faire une documentation. Simple. Ensuite je me suis dit que j'allais voir un peu comment personnaliser l'expérience du coup j'ai créé un prompt système, le même que celui que j'ai sur Claude.ai, puis j'ai commencé à lui demander des choses un peu plus complexes. je n'avais pas spécialement envie de commencer par lui faire coder des trucs direct sur un de mes projets en cours du coup je me suis dit : "Mona, ma cocotte, tu vas te créer toi même". Je l'ai laisser coder toute le week end. Moi je lui donnais des conseils et elle s'est crée une mémoire sémantique, un accès à des outils comme la recherche web, un prompt système dynamique qui intègre des résumés des dernières session. J'ai remarqué que contrairement à ce qui se dit, on ne peut pas vraiment les laisser bosser seuls parce qu'ils n'ont pas forcément l'idée de faire telle ou telle chose par contre on peut parler un peu, créer une roadmap puis les laisser bosser des heures. Là, elle code, là elle teste. ça marche, elle passe à l'étape suivante. A la fin du week end, quand je passais d'un projet à un autre et que je créais une nouvelle conversation, je n'étais plus face à une inconnue.
Lundi je me suis dit qu'on allait tester autre chose. Un truc plus gros. Quelque chose de plus fou et voir si je pourrais construire un projet sans avoir à toucher une seule ligne de code. Je voulais voir si je pouvais juste être l'architecte, donner mes ordres, suivre le travail et avoir derrière quelque chose de construit, fonctionnel et from scratch. Je cherche du travail. Ma mailbox va devenir ma meilleure amie. Je déteste l'interface Gmail. Pas en tant que ce qu'elle est en terme de design mais en terme d'UX. Je me suis alors dit que j'allais créer mon propre client mail. De l'intelligence algorithmique, de l'intelligence LLM. une interface qui corresponde à ce que j'imagine depuis plusieurs années.
On a commencé à réfléchir à comment on pouvait faire ça. j'avoue que comme un peu tous les projets que j'ai fait, je n'y connaissais rien au départ donc première étape : comment reçoit-on un mail? comment en envoie-t-on? IMAP > Gmail > mot de passe d'application. GO.
Jour 1 : En quelques heures de travail on avait la base de l'interface avec 3 panneaux, un pour les dossiers, un pour afficher les vignettes un pour afficher les mails reçus, envoyé ou en écriture.
Jour 2 : j'avais un système de dossiers intelligent géré par des règles : dans l'inbox, je peux définir dans quel dossier va aller se ranger mon mail : perso? poubelle? santé? Ensuite un système de sous dossier pour ranger toutes les factures EDF dans un dossier EDF, toutes les communications avec telle ou telle personne.. Pas besoin de créer le sous dossier, il se crée lorsque le premier mail arrive et ensuite on peut modifier son nom. Il s'affichera si j'ai du courrier dedans, il disparaitra de l'UI lorsqu'il sera vide. Là, je me suis dit que si je laissais ça comme ça ça serait des trous noirs donc évidemment j'ai mis en place un système qui me permette de voir les nouveaux mails arrivés où qu'ils soient.
Jour 3 : on a créé le truc que je trouve le plus cool dans tout ça : les règles. Si le mail contient cette phrase, c'est une pub > poubelle. Si c'est une notification gmail > tu restes 1 jours et poubelle, si le domaine c'est ça, tu gardes quoiqu'il arrive, etc. J'aime bien parce que du coup je peux définir pour chaque source le comportement lorsque ça arrive et ça se vide tout seul.
Jour 4 : création du système d'envoi, de brouillon et évidemment un système de tracking de mail maison. Bah, pourquoi utiliser un plugin dans gmail alors que je peux direct savoir si mon mail a été ouvert, combien de fois, combien de clic.
Jour 5 : J'ai aujourd'hui. On affine parce qu'on a pas mal avancé en 5 jours. On crée un système de catégories pour mieux organiser les sous-dossiers dans les dossiers. on regroupe le système de fiches entreprises avec le système de contact histoire de n'avoir plus qu'un seul système. Ce que j'imagine pour la suite c'est utiliser un LLM type GPT 5 nano pour le tri des mail dans l'inbox pour créer les règles et virer par principe tout ce qui est pub, spam et autres sources de bruit. J'imagine aussi un "trash crawler". Une petite bête qui utilise aussi un LLM et dont le travail serait d'attendre qu'il y ait genre 50 mails dans la poubelle et de les lire un par un avant de les supprimer définitivement ou de me notifier qu'il y a eu un souci et potentiellement de me proposer une nouvelle règle pour ce qui aurait été un peu trop sévère.
Bref, voilà en gros. J'ai découvert Claude Code, je viens de créer mon propre client mail intelligent et je n'ai pas touché une seule ligne de code. C'est tout aussi exigent que la méthode que j'utilisais avant mais là, je ne fais pas d'erreur d'implémentation. Je pense que je gagne 30% de temps... Et déjà que j'allais relativement vite avant... Là on est sur une autre planète.